Edge computing vs cloud is redefining how organizations balance speed, scale, and security in modern architectures, prompting IT teams to reconsider where data is processed, how decisions are made in real time, and what governance models best support continuous delivery across distributed environments, multi-site operations, and increasingly autonomous systems, while aligning with customer experience goals and developer velocity. As teams demand faster data processing at the source, they weigh trade-offs between distributing computation toward the network edge and relying on centralized data centers, a shift that directly affects latency in edge vs cloud and reshapes how applications stay resilient during network outages, outages that can ripple across manufacturing floors, hospitals, and logistics networks. By filtering, aggregating, and sometimes running lightweight analytics locally, edge deployments can enable fast data processing while preserving essential bandwidth for deeper analytics, model updates, and long-term storage in the cloud, ensuring a balanced approach to performance, cost, security, and the ongoing evolution of connected product ecosystems. At the same time, cloud computing differences in scale, governance, and the breadth of services—ranging from data lakes and AI training to security and compliance tooling—make centralized processing attractive for heavy analytics, batch workloads, and global coordination across multiple sites, regions, and partner networks. Choosing the right mix—often a hybrid approach—involves mapping latency requirements, data sensitivity, regulatory constraints, and total cost of ownership to real-world workloads, and identifying edge computing advantages that justify moving processing closer to the source while leveraging cloud capabilities for orchestration, scalability, and advanced analytics across the enterprise.
Alternative terms for this topic emphasize the same core trade-offs, such as near-edge processing, localized data handling, and the cloud-to-edge continuum. In practice, teams compare decentralized computing near sensors and gateways with centralized cloud platforms hosted by public or private providers, a concept often framed as fog computing that stresses data locality and rapid responses. LSI-friendly terms like distributed computing at the edge, edge-to-cloud integration, and network-edge orchestration help search engines connect the ideas of latency, bandwidth optimization, and governance. Together, these phrases guide readers toward a hybrid architecture where on-device inference and edge workflows feed into scalable cloud analytics and machine learning pipelines.
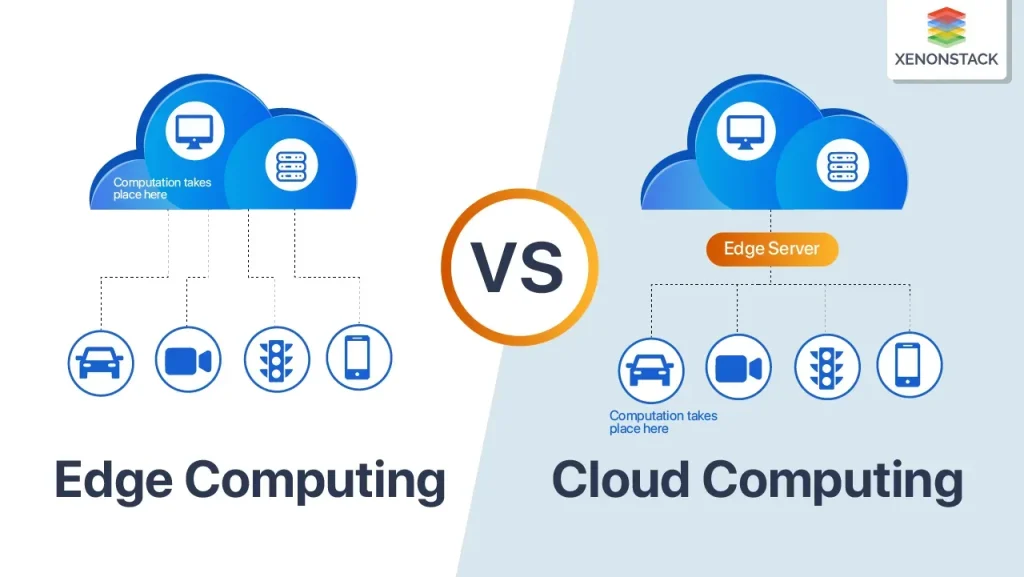
Edge computing vs cloud: Balancing latency, bandwidth, and real-time decisions
Edge computing vs cloud presents a structured choice about where data is processed to achieve fast data processing and timely insights. By moving critical computations closer to the data source, organizations can reduce latency and enable real-time actions, which is essential for applications like industrial automation, autonomous systems, and responsive IoT ecosystems. This distinction is central to optimizing latency in edge vs cloud scenarios, where the edge shines when milliseconds matter and the cloud offers expansive resources for larger-scale tasks.
In practice, most architectures blend both approaches to optimize performance and cost. Decision makers weigh latency requirements, bandwidth constraints, and data governance needs as they map out which workloads belong at the edge and which belong in the cloud. The goal is to leverage edge computing advantages for time-sensitive processing while reserving cloud computing differences—such as scalable compute, rich analytics, and centralized management—for heavier analyses and historical insights.
Fast data processing at the edge: Techniques for ultra-low-latency applications
Achieving ultra-low latency starts with processing data where it is generated. Edge devices perform filtering, aggregation, and lightweight analytics on-site, ensuring that only meaningful results traverse the network. Techniques like local inference, model quantization, and edge-optimized machine learning enable fast data processing without sending raw streams to the cloud, which is key to reducing latency in edge computing environments.
To scale fast data processing at the edge, organizations deploy micro data centers, gateways, and multi-access edge computing (MEC) frameworks that provide near-data processing power close to sensors and users. By orchestrating these resources, they maintain consistent performance, manage data locality, and support real-time decision making even when connectivity is imperfect.
Cloud computing differences: When centralized analytics and heavy workloads win
Cloud computing differences become most evident when workloads require massive compute, long-running analytics, or centralized governance. The cloud offers virtually unlimited scalability, advanced analytics, and robust data storage, making it the default choice for batch processing, ML model training at scale, and global data orchestration. For non-time-critical operations, centralized processing in the cloud delivers deep insights and powerful data science capabilities.
Latency considerations often steer workloads toward the cloud for tasks that tolerate longer response times but demand substantial computational resources. By centralizing data, organizations can unify governance, simplify security posture, and apply sophisticated analytics across diverse datasets, while still blending edge processing for time-sensitive actions where appropriate.
Edge computing advantages: Practical gains in privacy, resilience, and efficiency
Edge computing advantages include improved privacy and data sovereignty by keeping sensitive information closer to the source. Local processing reduces exposure during transmission and enables on-device compliance with regulatory requirements. This is especially important in healthcare, manufacturing, and other sensitive domains where data governance is a priority.
Beyond privacy, edge deployments enhance resilience and bandwidth efficiency. When networks are intermittent or congested, edge nodes can operate autonomously and sync with the cloud when connectivity returns. This resilience, combined with reduced data transfer, translates into lower bandwidth costs and more predictable performance for critical operations.
Hybrid architectures: Blending edge and cloud for optimal performance
Hybrid architectures combine the strengths of edge and cloud to deliver fast data processing while preserving scalability. A common pattern is edge inference for real-time decisions, with cloud-based training and batch processing feeding improved models back to edge devices. This approach leverages the edge computing advantages for immediacy and the cloud’s capacity for deep analytics and long-term data storage.
Multi-access edge computing (MEC) extends these benefits by providing a coordinated, low-latency edge layer across distributed locations. Hybrid designs require careful orchestration of data flows, model updates, and governance policies to ensure data quality and security while maintaining continuous operation across sites.
Security and governance in edge and cloud environments
Security and governance must be treated as a lifecycle that spans both edge and cloud. At the edge, secure boot, encrypted storage, and tamper-evident devices protect against physical threats, while in transit, strong encryption and mutual authentication guard data as it moves across nodes or to the cloud. In the cloud, robust IAM, compliance programs, and incident response capabilities help maintain a secure ecosystem.
A cohesive strategy treats edge and cloud as parts of a single, governed system. Consistent data classification, retention policies, and access controls enable unified security posture and compliant data handling. This holistic approach supports reliable, scalable operations and aligns with the broader objective of achieving fast data processing without compromising governance.
Frequently Asked Questions
Edge computing vs cloud computing: what is the difference and when should you use each?
Edge computing moves processing closer to data sources (edge nodes, gateways) to reduce latency and bandwidth use, while cloud computing centralizes processing in data centers or cloud platforms for scalable analytics and long-term storage. Use edge computing vs cloud computing when latency matters or connectivity is limited; rely on the cloud for heavy computation, training, and global data governance. A hybrid approach often delivers the best balance.
How does latency in edge vs cloud impact fast data processing in time-sensitive applications?
Latency in edge vs cloud affects the speed at which decisions are made. Processing at the edge enables millisecond-scale inference and action, while cloud processing introduces network round-trips. Fast data processing is achieved by keeping time-critical tasks at the edge and sending summaries or non-urgent analytics to the cloud for deeper insights.
What are the edge computing advantages for real-time analytics compared with cloud computing?
Edge computing advantages include ultra-low latency, reduced bandwidth consumption, offline operation, and improved privacy by keeping data local. Cloud computing complements by providing scalable analytics, training on large data, and centralized governance. Together, they support real-time analytics with broader context.
What are the cloud computing differences that matter for scalability, governance, and cost?
Cloud computing differences include elastic resource provisioning, managed services, and broad toolchains for analytics and governance. It enables scalable workloads, centralized IAM and security, and pay-as-you-go pricing. Understanding these differences helps plan cost, data governance, and policy enforcement across a hybrid environment.
Why is a hybrid edge and cloud architecture often the best approach for fast data processing?
A hybrid edge and cloud architecture combines edge inference for real-time decisions with cloud training and batch analytics. This setup minimizes latency, preserves bandwidth, and maintains scalable analytics, delivering fast data processing while enabling continuous model improvement.
How should organizations decide which workloads run at the edge vs cloud to optimize latency and throughput?
Decide by analyzing latency requirements, data volume, connectivity stability, and compliance needs. Run time-sensitive tasks at the edge, move compute-heavy or historical workloads to the cloud, and use data flow mapping to migrate workloads as needs evolve. This aligns edge vs cloud with fast data processing goals.

